Background
If you are not familiar with the Stingray Entity system you can find good resources to catch up here:
The Entity system is a very central part of the future of Stingray and as we integrate it with more parts new requirements pops up. One of those is the ability to interact with Entity Components via the visual scripting language in Stingray - Flow. We want to provide a generic interface to Entites in Flow without adding weight to the fundamental Entity system.
To accomplish this we added a “Property” system that Flow and other parts of the Stingray Engine can use which is optional for each Component to implement in addition to having its own specialized API. The Property System enables an API to read and write entity component properties using the name of component, the property name and the property value. The Property System needs to be able to find a specific Component Instance by name for an Entity, and the Entity System does not directly track an Entity / Component Instance relationship. It does not even track the Entity / Component Manager relationship.
So what we did was to add the Entity Index, a registry where we add all Component Instances created for an Entity as it is constructed from an Entity Resource. To make it usable we also added the rule that each Component in an Entity Resource should have a unique name within the resource so the user can identify it by name when using the Flow system.
In order for the Flow system to work we need to be able to find a specific component instance by name for an Entity so we could get and set properties of that instance. This is the job of the Entity Index. In the Entity Index you can register an Entitys components by name so you later can do a lookup.
Property System and Entity Index
When creating an Entity we use the name of the component instance together with the component type name, i.e the Component Manager, and create an
Entity Index that maps the name to the component instance and the
Component Manager. In the Stingray Entity system an Entity cannot have two component instances with the same name.
Example:
Entity
- Transform - Transform Component
- Fog - Render Data Component
- Vignette - Render Data Component
For this Entity we would instantiate one Transform Component Instance and two Render Data Component Instances. We get back an InstanceId for each Component Instance which can be used to identify which of Fog or Vignette we are talking about even though they are created from the same Entity using the same Component Manager.
We also register this in the Entity Index as:
| Key |
Value |
| Entity |
Array<Components> |
The Array<Components> contains one or more entries which each contain the following:
| Components |
| Component Manager |
| InstanceId |
| Name |
Lets add the a few entities and components to the Entity Index:
entity_1.id
| Name |
Component Manager |
InstanceId |
| hash(“Transform”) |
&transform_manager |
13 |
| hash(“Fog”) |
&render_data_manager_1 |
4 |
| hash(“Vignette”) |
&render_data_manager_1 |
5 |
entity_2.id
| Name |
Component Manager |
InstanceId |
| hash(“Transform”) |
&transform_manager |
14 |
| hash(“Fog”) |
&render_data_manager_1 |
6 |
| hash(“Vignette”) |
&render_data_manager_1 |
7 |
entity_3.id
| Name |
Component Manager |
InstanceId |
| hash(“Transform”) |
&transform_manager |
2 |
| hash(“Fog”) |
&render_data_manager_2 |
4 |
| hash(“Vignette”) |
&render_data_manager_2 |
5 |
This allows Flow to set and get properties using the Entity and the Component Name. Using the Entity and Component Name we can look up which Component Manager has the component instance and which InstanceId it has assigned to it so we can get the Instance and operate on the data.
The problem with this implementation is that it will become very large - we need a large registry with one key-array pair for each Entity where the array contains one entry for each Component Instance for the Entity, not very efficient as the number of entites grow. There is no reuse at all in the Entity Index - and it can’t be - each entry in the index is unique with no overlap.
Here are some measurements using a synthetic test that creates entities, add and looks up components on the entities and deleted entities. It deletes parts of the entities as it runs and does garbage collection. The number entities given in the tables is the total number created during the test, not the number of simultaneous entities which varies over time. The entities has 75 different types of component compositions, ranging from a single component to eleven for other entities. The test is single threaded and no locking besides some on the memory sub system which makes the times match up well with CPU usage.
| Entity Count |
Test run time (s) |
Memory used (Mb) |
Time/Entity (us) |
| 10k |
0.01 |
5.79 |
0.977 |
| 20k |
0.01 |
5.79 |
0.488 |
| 40k |
0.03 |
11.88 |
0.732 |
| 80k |
0.06 |
11.88 |
0.732 |
| 160k |
0.13 |
25.69 |
0.793 |
| 320k |
0.32 |
31.04 |
0.977 |
| 640k |
1.08 |
55.90 |
1.648 |
| 1.28m |
2.58 |
65.82 |
1.922 |
| 2.56m |
6.35 |
65.55 |
2.366 |
| 5.12m |
13.42 |
120.55 |
2.500 |
| 10.24m |
25.69 |
130.55 |
2.393 |
As you can see we start to take longer and longer time and use more and more memory as we double the number of entities and as we get to the larger numbers the time and memory increases pretty dramatically.
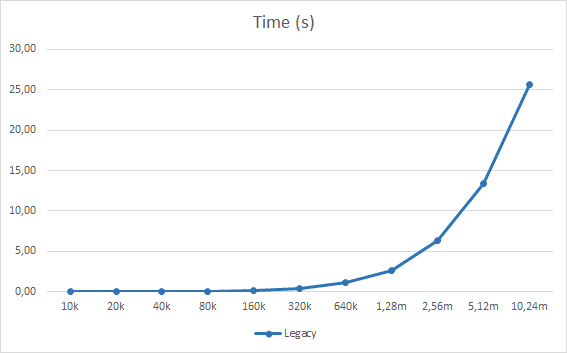
Since we plan to use the entity system extensively we need an index that is more efficient with memory and scales more linearly in CPU usage.
Shifting control of the InstanceId
The InstanceId is defined to be unique to the Entity instance for a specific Component Manager - it does not have to be unique for all components in a Component Manager, nor does it have to be unique across different Component Managers.
The create and lookup functions for an Component Instance looks like this:
InstanceWithId instance_with_id = transform_manager.create(entity);
InstanceId my_transform_id = instance_with_id.id;
.....
Instance instance = transform_manager.lookup(entity, my_transform_id);
The interface is somewhat confusing since the create function returns both the component instance id and the instance. This is done so you don’t have to do a lookup of the instance directly after create. As you can see we have no knowledge of what the resulting InstanceId will be so we can’t make any assumptions in the Entity Index forcing us to have unique entries for each Component instance of every Entity.
But we already set up the rule that in the Entity Resource, each Component should have a unique name for the Property System to work - this is a new requirement that was added at a later stage than when designing the initial Entity system. Now that it is there we can make use of this to simplify the Entity Index.
Instead of letting each Component Manager decide the InstanceId we let the caller to the create function decide the InstanceId. We can decide that the InstanceId should be the 32-bit hash of the Component Name from the Entity Resource. Doing this will restrict the possible optimization that a component manager could do if it had control of the InstanceId, but so far we have had no real use case for it and the benefits of changing this are greater than the loss of a possible optimization that we
might do sometime in the future.
So we change the API like this:
Instance instance = transform_manager.create(entity, hash("Transform"));
.....
Instance instance = transform_manager.lookup(entity, hash("Transform"));
Nice, clean and symmetrical. Note though that the InstanceId is entierly up to the caller to control, it does not have to be a hash of a string. It must be unique for an Entity within a specific component manager. Having it work with the Entity Index and the Property System the InstanceId needs to be unique across all Component Instances in all Component Managers for each Entity instance. This is enforced when an Entity is created from a resource but not when constructing Component Instances by hand in code. If you want a component added outside the resource construction to work with the Property System care needs to be taken so it does not collide with other names of component instances for the Entity.
Lets add the entities and components again using the new rule set, the Entity Index now look like this:
entity_1.id
| Name |
Component Manager |
InstanceId |
| hash(“Transform”) |
&transform_manager |
hash(“Transform”) |
| hash(“Fog”) |
&render_data_manager_1 |
hash(“Fog”) |
| hash(“Vignette”) |
&render_data_manager_1 |
hash(“Vignette”) |
entity_2.id
| Name |
Component Manager |
InstanceId |
| hash(“Transform”) |
&transform_manager |
hash(“Transform”) |
| hash(“Fog”) |
&render_data_manager_1 |
hash(“Fog”) |
| hash(“Vignette”) |
&render_data_manager_1 |
hash(“Vignette”) |
entity_3.id
| Name |
Component Manager |
InstanceId |
| hash(“Transform”) |
&transform_manager |
hash(“Transform”) |
| hash(“Fog”) |
&render_data_manager_2 |
hash(“Fog”) |
| hash(“Vignette”) |
&render_data_manager_2 |
hash(“Vignette”) |
As we now see the Instance Id column now contain redundant data - we only need to store the Component Manager pointer. We use the Entity and hash the component name to find our Component Manager which can be used to look up the Instance.
entity_1.id
| Name |
Component Manager |
| hash(“Transform”) |
&transform_manager |
| hash(“Fog”) |
&render_data_manager_1 |
| hash(“Vignette”) |
&render_data_manager_1 |
entity_2.id
| Name |
Component Manager |
| hash(“Transform”) |
&transform_manager |
| hash(“Fog”) |
&render_data_manager_1 |
| hash(“Vignette”) |
&render_data_manager_1 |
entity_3.id
| Name |
Component Manager |
| hash(“Transform”) |
&transform_manager |
| hash(“Fog”) |
&render_data_manager_2 |
| hash(“Vignette”) |
&render_data_manager_2 |
We now also see that the lookup array for entity_1 and entity_2 are identical so two keys could point to the same value.
Options for implementation
We could opt for an index that has a map from entity_id to a list or map of entries for lookup:
entity_1.id = [ hash("Transform"), &transform_manager ], [ hash("Fog"), &render_data_manager_1 ], [ hash("Vignette"), &render_data_manager_1 ]
entity_2.id = [ hash("Transform"), &transform_manager ], [ hash("Fog"), &render_data_manager_1 ], [ hash("Vignette"), &render_data_manager_1 ]
entity_3.id = [ hash("Transform"), &transform_manager ], [ hash("Fog"), &render_data_manager_2 ], [ hash("Vignette"), &render_data_manager_2 ]
We should probably not store the same entry lookup list multiple times if it can be resused by multiple entity instances as this wastes space, but at any time a new component instance can be added or removed from an entity and its entry list would then change - that would mean administrating memory for the lookup lists and detecting when two entities starts to diverge so we can make a new extended copy of the entry list for the changed entity. We should probably also remove lookup lists that are no longer used as it would waste memory.
Entity and component creation
The call sequence for creating entities from resources (or even programmatically) looks something like this:
Entity e = create();
Instance transform = transform_manager.create(e, hash("Transform"));
Instance fog = render_data_manager_1.create(e, hash("Fog"));
Instance vignette = render_data_manager_1.create(e, hash("Vignette"));
In this scenario we could potentially build a entity lookup list for the entity which contains lookup for the transform, fog and vignette instances:
entity_index.register(e, [ hash("Transform"), &transform_manager ], [ hash("Fog"), &render_data_manager_1 ], [ hash("Vignette"), &render_data_manager_1 ]);
But as stated previously - component instances can be added and removed at any point in time making the lookup table change during the lifetime of the Entity. We need to be able to extend it at will, so it should look something like this:
Entity e = create();
Instance transform = transform_manager.create(e, hash("Transform"));
entity_index.register(e, [ hash("Transform"), &transform_manager ]);
Instance fog = render_data_manager_1.create(e, hash("Fog"));
entity_index.register(e, [ hash("Fog"), &render_data_manager_1 ]);
Instance vignette = render_data_manager_1.create(e, hash("Vignette"));
entity_index.register(e, [ hash("Vignette"), &render_data_manager_1 ]);
Now we just extend the lookup list of the entity as we add new components. This means that two entities that started out life as having identical lookup lists after being spawned from a resource might diverge over time so the Entity Index needs to handle that.
Component Instances can also be destroyed, so we should handle that as well. Even if we do not remove component instances things will still work - if we keep a lookup to an Instance that has been removed we would then just fail the lookup in the corresponding Component Manager. It would lead to waste of memory though, something we need to be aware of going forward.
Building a Prototype chain
Looking at how we build up the Component instances for an Entity it goes something like this: first add the Transform, then add Fog and finally Vignette. This looks sort of like an inheritance chain…
Lets call a lookup list that contains a specific set of entry values a
Prototype.
An entity starts with an empty lookup list that contains nothing [], this is the base Prototype, lets call that P0.
- Add the “Transform” component and your prototype is now P0 + [&transform_manager, “Transform”], lets call that prototype P1.
- Add the “Fog” component, now the prototype is P1 + [&render_data_manager_1, “Fog”] - call it P2.
- Add the “Vignette” component, now the prototype is P2 + [&render_data_manager_1, “Vignette”] - call it P3.
Your entity is now using the prototype P3, and from that you can find all the lookup entries you need.
The prototype registry will contain:
P0 = []
P1 = [] + [&transform_manager, "Transform"]
P2 = [] + [&transform_manager, "Transform"] + [&render_data_manager_1, "Fog"]
P3 = [] + [&transform_manager, "Transform"] + [&render_data_manager_1, "Fog"] + [&render_data_manager_1, "Vignette"]
If you create another entity which uses the same Components with the same names you will end up with the same prototype:
Create entity_2, it will have the empty prototype P0.
- Add the “Transform” component and your prototype now P1.
- Add the “Fog” component, now the prototype is P2.
- Add the “Vignette” component, now the prototype is P3.
We end up with the same prototype P3 as the other entity - as long as we add the entities in the same order we end up with the same prototype. For entites created from resources this will be true for all entities created from the same entity resource. For components that are added programatically it will only work if the code adds components in the same order, but even if they do not
always do this we still will have a very large overlap for most of the entities.
Lets look at the third example where we do not have an exact match, entity_3:
Create entity_3, it will have the empty prototype P0.
- Add the “Transform” component and your prototype is now P0 + [&transform_manager:Transform, “Transform”] = P1.
- Add the “Fog” component - this render data component manager is not the same as entity_1 and entity_2 so we get P1 + [&render_data_manager_2, “Fog”], this does not match P2 so we make a new prototype P4 instead.
- Add the “Vignette” component, now the prototype is P4 + [&render_data_manager_2, “Vignette”] -> P5.
The prototype registry will contain:
P0 = []
P1 = [] + [&transform_manager, "Transform"]
P2 = [] + [&transform_manager, "Transform"] + [&render_data_manager_1, "Fog"]
P3 = [] + [&transform_manager, "Transform"] + [&render_data_manager_1, "Fog"] + [&render_data_manager_1, "Vignette"]
P4 = [] + [&transform_manager, "Transform"] + [&render_data_manager_2, "Fog"]
P5 = [] + [&transform_manager, "Transform"] + [&render_data_manager_2, "Fog"] + [&render_data_manager_2, "Vignette"]
Storage of the prototype
We can either for each prototype store all the component lookup entries - this makes it easy to get all the component instance look-ups in one go at the expense of memory due to data duplication. Each entity will store which prototype it uses.
- entity_1 -> P3
- entity_2 -> P3
- entity_3 -> P5
The prototype registry now contains:
P0 = []
P1 = [] + [&transform_manager, "Transform"]
P2 = [] + [&transform_manager, "Transform"] + [&render_data_manager_1, "Fog"]
P3 = [] + [&transform_manager, "Transform"] + [&render_data_manager_1, "Fog"] + [&render_data_manager_1, "Vignette"]
P4 = [] + [&transform_manager, "Transform"] + [&render_data_manager_2, "Fog"]
P5 = [] + [&transform_manager, "Transform"] + [&render_data_manager_2, "Fog"] + [&render_data_manager_2, "Vignette"]
Some of the entries (P2 and P4) could technically be removed since they are not actively used - we would need to temporarily re-create them as new entries with the same structure were added.
A different option is to actually
use the intermediate entries by referencing them, like so:
P0 = []
P1 = P0 + [&transform_manager, "Transform"]
P2 = P1 + [&render_data_manager_1, "Fog"]
P3 = P2 + [&render_data_manager_1, "Vignette"]
P4 = P1 + [&render_data_manager_2, "Fog"]
P5 = P4 + [&render_data_manager_2, "Vignette"]
Less wasteful but requires lookup up in the chain to find all the components for an entity. On the other hand we can make this very efficient storage-wise by having a lookup table like this:
Map from Prototype to {base_prototype, component_manager, component_name}. The prototype data is small and has no dynamic size so they can be stored very effiently.
The prototype will add all the prototypes to the same prototype map and since the HashMap implementation lookup gives us O(1) lookup cost, traversing the chain will only cost us the potential cache-misses of the lookup. Since the hashmap is likely to be pretty compact (via prototype reuse) this hopefully should not be a huge issue. If it turns out to be, a different storage approach might be needed trading memory use for lookup speed.
Since the amount of data we store for each Prototype would be very small - roughly 16 bytes - we can be a bit more relaxed with unused prototypes - we do not need to remove them as aggressively as we would if each prototype contained a complete lookup table for all components.
Building the Prototype index
So how do we “name” the prototypes effectively for fast lookup? Well, the first lookup would be Entity -> Prototype and then from Prototype -> Prototype definition.
A simple approach would be hashing - use the content of the Prototype as the hash data to get a unique identifier.
The first base prototype has an empty definition so we let that be zero.
To calculate a prototype, mix the prototype you are basing it of with the hash of the protoype data, in our case we hash the Component Manager pointer and Component Name, and mix it with the base prototype.
Prototype prototype = mix(base_prototype, mix(hash(&component_manager), hash(component_name)))
The entry is stored with the prototype as key and the value as [base_prototype, &component_manager, component_name].
When you add a new Component to an entity we add/find the new prototype and update the Entity -> Prototype map to match the new prototype.
So, we end up with a structure like this:
struct PrototypeDescription {
Prototype base_prototype;
ComponentMananger *component_manager;
IdString32 component_name;
}
Map<Entity, Prototype> entity_prototype_lookup;
Map<Prototype, PrototypeDescription> prototypes;
void register_component(Entity, ComponentManager, component_name)
{
Prototype p = entity_prototype_lookup[Entity];
Prototype new_p = mix(p, mix(hash(ComponentManager), hash(component_name)));
if (!prototypes.has(new_p))
prototypes.insert(new_p, {p, &ComponentManager, component_name});
enity_index[Entity] = new_p;
}
ComponentMananger *find_component_manager(Entity, component_name)
{
Prototype p = entity_index[Entity];
while (p != 0)
{
PrototypeDescription description = prototypes[p];
if (description.component_name == component_name)
return description.component_manager;
p = description.base_prototype;
}
return nullptr;
}
This could lead to a lot of hashing and look-ups but we can change the api to register new components to multiple Entities in one go which would lead to dramatically less number of hashing and look-ups, we already do that kind of optimization when creating entities from resources so it would be a natural fit. Also, we can easily cache the base prototype index to avoid more of the hash look-ups in
find_component_manager.
Measuring the results
Lets run the synthetic test again and see how our new entity index match up to the old one.
| Entity Count |
Test run time (s) |
Memory used (Mb) |
Time/Entity (us) |
| 10k |
0.01 |
0.26 |
0.977 |
| 20k |
0.01 |
0.51 |
0.488 |
| 40k |
0.03 |
0.99 |
0.832 |
| 80k |
0.06 |
0.99 |
0.610 |
| 160k |
0.11 |
0.99 |
0.671 |
| 320k |
0.23 |
0.99 |
0.702 |
| 640k |
0.46 |
0.99 |
0.702 |
| 1.28m |
0.94 |
0.99 |
0.700 |
| 2.56m |
1.88 |
0.99 |
0.700 |
| 5.12m |
3.78 |
0.99 |
0.704 |
| 10.24m |
7.57 |
0.99 |
0.705 |
The run time now scales very close to linearly and is overall faster than the old implementation. Most notable is the win when using a lot of entities. Memory usage has gone down as well and the time/entity is also scaling more gracefully.
Memory usage looks a little strange but there is an easy explanation - the mapping from entity to prototype is using almost all that memory (via a hashmap) and the actual prototypes takes less than 30 Kb. Note that the old index uses the same amount of memory for the Entity to Prototype mapping.
Lets compare the graphs between the old and new implementation:
| Entity Count |
Time New (s) |
Time Legacy (s) |
Memory New (Mb) |
Memory Legacy (Mb) |
Time/Entity New (us) |
Time/Entity Legacy (us) |
| 10k |
0.01 |
0.01 |
0.26 |
5.79 |
0.977 |
0.977 |
| 20k |
0.01 |
0.01 |
0.51 |
5.79 |
0.488 |
0.488 |
| 40k |
0.03 |
0.03 |
0.99 |
11.88 |
0.832 |
0.732 |
| 80k |
0.05 |
0.06 |
0.99 |
11.88 |
0.610 |
0.732 |
| 160k |
0.11 |
0.13 |
0.99 |
25.69 |
0.671 |
0.793 |
| 320k |
0.23 |
0.32 |
0.99 |
31.04 |
0.702 |
0.977 |
| 640k |
0.46 |
1.08 |
0.99 |
55.90 |
0.702 |
1.648 |
| 1.28m |
0.94 |
2.58 |
0.99 |
65.82 |
0.700 |
1.922 |
| 2.56m |
1.88 |
6.53 |
0.99 |
65.55 |
0.700 |
2.366 |
| 5.12m |
3.78 |
13.42 |
0.99 |
120.55 |
0.704 |
2.500 |
| 10.24m |
7.57 |
25.69 |
0.99 |
130.55 |
0.705 |
2.393 |
Looks like a pretty good win.
Final words
By taking into account the new requirements as the Entity system evolved we were able to create a much more space efficient and more performant Entity Index.
The implementation chosen here has focused on reducing the amount of data we use in the Entity Index at the cost of lookup complexity, I think this is the right trade-of, especially since it performs better as well. Since the interface for the Entity Index is fairly non-complex and does not dictate how we store the data we could change the implementation to optimize for lookup speed if need be.


















































